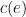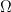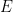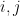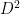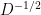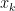Here are some previous informal notes I’ve taken on the paper titled “Diffusion Maps and Coarse Graining: A Unified Framework for Dimensionality Reduction, Graph Partitioning, and Data Set Parameterization” authored by Stephane Lafon and Ann B. Lee. In this discussion, I will explore a core concept from the paper: the concept of “diffusion distance.” We’ll see how it relates to the spectral decomposition of the random walk matrix, or—as demonstrated in the proof—of the normalized Laplacian matrix. This concept was introduced in an earlier work by Lafon and Coifman and has been revisited in this paper and several others. A related concept is found in the Laplacian Eigenmaps paper, which employs the eigenvectors of the normalized Laplacian matrix to map data points while preserving the geometric structure of the data, although it doesn’t consider the eigenvalues in its mapping. Next, I’ll delve into the primary insights of Diffusion Maps, but first, let’s cover some foundational material.
Markov Chains and Random Walks
The connection between Markov Chains and Random walks is well known and has been the object of focus of several books including the well known Doyle-Snell book and the Aldous-Fill book. Let’s begin with few definitions.
Definition 2: Consider a weighted graph G(V,E,c) where . We will call from now on the weight of an edge as the conductance of that edge and the inverse quantity the resistance of the edge (note that already we have started thinking of the edges as resistors whose conductances are given by the edges or we have made a bad naming choice which is not the case here). Consider now the Markov Chain defined in the following way: when we are in node x we pick one of its neighbors with probability proportional to the conductance of the edge connecting them. The transition probability from x to y therefore is where is the normalization constant which is equal to the weighted degree of that node. We call this process weighted random walk on G(V,E,c).
Now we can proceed and discuss about certain aspects of the connection. The first main observation is that we can think interchangeably of weighted random walks and reversible Markov chains. This by itself is the first connection which will then lead us in connecting standard concepts of Markov Chains like commute times, hitting times with electrical quantities like the effective resistance, but we will discuss these in a next post.
Every reversible Markov Chain is a weighted random walk on a network
Before discussing our claim above, let’s first discuss the other direction of the claim, i.e., a weighted random walk on a graph is described by a reversible Markov Chain. It is indeed not hard to show that the probability distribution given by is stationary for the random walk in definition 2. Clearly the Markov chain is reversible with respect to since the detailed balance equations are satisfied:
Now that we verified the inverse direction of our claim, we will show our claim, i.e., that we can think of any reversible Markov Chain as a weighted random walk on a network. Suppose our Markov Chain is defined by the transition matrix on the state space where such that is reversible with respect to a probability distribution . Define a graph with vertex set and edge set containing as edges all pairs whenever (observe that since our chain is reversible P(x,y)>0 implies directly P(y,x)>0 so we are consistent). Now we define the conductance of our edge to be . Clearly, the weighted degree of node x which is the sum of the conductances of all edges incident to x is and the transition matrix is P.
Now, without going into the formal details of proving that finite irriducible Markov Chains converge to their stationary distribution we give some intuition. Assume that we have the graph shown in the figure below. The graph is consisted of two large cliques and a single edge connecting them. For convention, I will call the clique on the left community A and the clique on the right community B. Assume now that we perform random walks on our graph and we restrict ourselves to perform steps. Assume is not long enough in order to reach the stationary distribution. Intuitively, starting from a node x in community A it is hard to get to the community B. Therefore, again intuitively, for a that is not “too small” and not “too big” we can collect useful information concerning the topology of the graph. This idea is a key idea for the method we will describe next. There are few observations which are worth noting in our example. When nodes x and y belong to the same community then the probability of starting at node i and hitting node j for some is fairly high. Of course note that the other direction of this claim does not necessarily hold. Furthermore given that x and y belong to the same community the transition probabilities they see the rest of the nodes in the “same way” with respect to transition probabilities. Specifically, for every .
Two cliques connected by a single edge
Diffusion Maps
Assume that our input is a dataset consisting of points in dimensions, i.e., . The first step is to create a graph from . There exists recent work by Daitch, Spielman and Kelner which introduces a principled way to create such graphs, but for simplicity let’s assume that we either create a k-nearest neighbor graph or that we use the kernel that assigns the weight to the edge between nodes . Now, that we have the graph, we can perform random walks as described in the section before. For a given that as I mentioned before should not be “too big” or “too small” in order to avoid reaching the stationary distribution and at the same time obtain information about the topology of the graph respectively the authors define the diffusion distance to be . If you take a look in their paper, you will see that in the denominator they use but as we explained before this is proportional to the degree of that node so the of this post will have to be multiplied by the sum of all the degrees of the graph to obtain the of their paper. I also prefer the notation since I will use the symbol to denote the degree. It is worth noting that we can write this expression in terms of matrix vector multiplications as , where D is the diagonal matrix containing in its -th diagonal entry the degree of node . The main claim of the paper is that this distance which as you see tries to give less importance to higher degree nodes in the summation, simply because they are easier to be reached can be expressed in terms of the spectrum of the random walk matrix. Recall that the random walk matrix, i.e., the transition probability matrix is equal to where is the adjacency matrix of the (weighted) graph and that each matrix has two kinds of eigenvectors, the right () and the left (), related with the column and the row space of the matrix. Here is their main result stated as a theorem.
Theorem (Diffusion Maps): Let (n=#nodes) be the eigenvalue-right eigenvector pairs of . Then the diffusion distance satisfies the following equation: .
Observe that the summation index begins at 2; however, starting from 1 would be inconsequential as the first eigenvector is constant (recall that is stochastic, implying that the vector of all ones is an eigenvector with eigenvalue 1. For additional details, refer to the proof provided below). Here follows the proof:
Proof: Let’s first consider the random walk matrix . This matrix has real eigenvalues (note that even if the graph is symmetric it is not necessary that is symmetric because of the normalization using ) because with a simple similarity transformation we obtain that and have the same eigenvalues, where and is clearly symmetric (so the spectral theorem applies). As a minor point note that since the graph is connected then no node has degree 0 and thus multiplying by is fine. Furthermore, the eigenvectors of both left and right can be obtained with 1-1 correspondence from the eigenvectors of . Here is how. For the right assume is an eigenvector of . This means . Substituting for and multiplying from the left with we obtain where . For the left assume is a left eigenvector of . This means which implies that where . So after all this we can do the following for a while: forget the “ugly” non-symmetric matrix P and think in terms of , which is the Normalized Laplacian matrix essentially (I say essentially since sometimes you flip the spectrum by negating and the shifting it by 1 by adding the identity. By the way, observe that by the Perron Frobenius theorem and the fact that the matrix is stochastic -Gershgorin circles give an obvious bound of 1 to the maximum eigenvalue which is attainable by the stationary distribution- that ). The last thing we want to “take out” from is the relation for the eigenvectors. Again, by the spectral theorem the eigenvectors of form an orthonormal basis for . This translates to the following if i=j, otherwise 0. Now we write the transition matrix as a sum of rank 1 matrices, produced by the outerproducts of the right and left eigenvectors. Specifically, . Extracting the -th row of this matrix gives as that where is the -th eigenvector of . Now we take this expression and we substitute in the expression of and we obtain the following:
, since the cross terms by the orthogonality of the ‘s are zero. Also since the first eigenvector is the constant we can start the summation from . Q.E.D.
Code
You can findcodefor the Diffusion Maps online through the web site of Ann Lee.