Numerous high-impact applications rely on dense subgraph discovery, including anomaly detection and security, community detection in social networks, and the Web graph, detection of protein complexes in protein interaction networks, and extraction of highly correlated entities from a relevance graph. The latter type of graphs is used to encode pairwise similarities among entities, e.g., time series, and is ubiquitous in data science applications. Two major formulations for dense subgraph discovery are the maximum clique problem and the densest subgraph problem (DSP). The former is a notoriously hard problem, whereas the latter is poly-time solvable and lies at the core of large-scale data mining.
Denser than the Densest Subgraph: A heuristic approach for large-near clique extraction
In this paper, we define a novel density function, which gives subgraphs of much higher quality than densest subgraphs: the graphs found by our method are compact, dense, and with smaller diameter. We show that the proposed function can be derived from a general framework, which includes other important density functions as subcases and for which we show interesting general theoretical properties. To optimize the proposed function we provide an additive approximation algorithm and a local-search heuristic. Both algorithms are very efficient and scale well to large graphs.
Code
Publications
The  -clique densest subgraph problem: a principled approach for large-near clique extraction
-clique densest subgraph problem: a principled approach for large-near clique extraction

My work introduced the 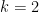
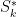


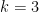

Code
Publications
- Scalable Large Near-Clique Detection in Large-Scale Networks via Sampling
- The
-clique Densest Subgraph Problem
Densest Subgraph Problem in the Streaming Model
Bahmani et al. first provided a 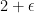



Publications
- Scalable Large Near-Clique Detection in Large-Scale Networks via Sampling
- Space- and Time-Efficient Algorithm for Maintaining Dense Subgraphs on One-Pass Dynamic Streams
Densest Subgraph Problem for Dynamic Graphs
In our STOC 2015 paper, we provide state-of-the-art results for the DSP on time-evolving graphs. For more details, see here.
Dense Subgraph Discovery, KDD Tutorial
In 2015, Aris Gionis and I gave a tutorial at KDD on dense subgraph discovery. You can watch the Youtube videos from here.
