Can we automatically infer social circles from an ego-network?
Learning Latent Features in Social Networks and Overlapping Correlation Clustering
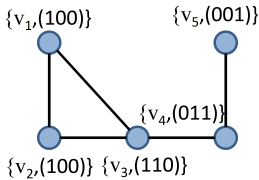
Suppose there exist five agents, each interested or not in each out of three news categories {business, entertainment, sports}. This information is encoded as binary vertex features. Based on their interests, they decide to connect, say with probability 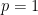
The key question we study is the following.
Given an undirected graph
, a latent labeling
, where
is the number of binary vertex features and is part of the input, and a probabilistic model of how nodes connect depending on the number of common interests, can we infer the labeling
?
Contributions
-
Modeling. We depart from the deterministic model we described above by introducing a simple probabilistic generative model with the following property: the probability of an edge between two vertices is a non-decreasing function of their common features.
-
Hardness and guarantees. We show that maximizing the log-likelihood function is NP-hard by proving that it subsumes as a special instance the overlapping correlation clustering problem. We provide combinatorial insights by connecting the machine learning problem with specific graph sub-structures. Then, we provide a rapidly mixing Markov chain for learning latent features.
-
Scalability. Our method is more than 2,400 faster than a state-of-the-art machine learning method.
-
Performance. Our method is able to learn high quality latent labelings. On Twitter, it outperforms or performs comparably well to BigClam, and outperforms various other methods.
