
Logistic regression coefficients. Edge disjoint paths of short length are informative features. For details, see our paper.
Predicting signed interactions
Ιnteractions in social media involve both positive and negative relationships. For example Slashdot, a popular web site with news for nerds, introduced in 2002 the Slashdot Zoo, where online users can tag others as friends or foes. This motivates the following interesting and important question, that was first asked in this paper:
Can we predict whether an interaction will be positive or negative?
Another closely related question is the following. Instead of being given the social network, we can query pairs of nodes, and learn whether their interaction is positive or negative. However, the answer provided to us is correct with probability 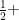

Under the assumption that the friend of my friend is my friend, and the enemy of my friend my enemy, can we recover all signs correctly with high probability? If yes, what is the smallest number of queries required?
Paper
Contributions
We have proved using random graph theory and Fourier analysis that (roughly) 

Code
Python code and a demo are available on Github. Our method is able to achieve high levels of accuracy, improving prior work.

Accuracy using 10-fold cross validation and different subset of features, broken down by embeddedness lower bounds (i.e., embeddedness of a pair of nodes is the number of common neighbors). For details, see our paper.
