Suppose there is an underlying 1 dimensional histogram stored in the cloud. As a concrete example, consider the distribution of bank deposits (x-axis is the amount of dollars, and the y-axis is the count of accounts). For simplicity let’s assume that all the amounts of money deposited are integers within the range 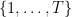

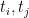
![i,j \in [n]](https://s0.wp.com/latex.php?latex=i%2Cj+%5Cin+%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002)
By Chernoff