Let’s say that you have 100$ and you want to invest your money wisely. There are two hedge funds that interest you, both of which have the same expected return. How should you invest your 100$? Does it matter if you split it in half, or if you invest all of your money in one of the two? Well, intuitively you want to be as sure as possible that you will be actually getting your profit, i.e., avoid risk as much as possible. That’s where variance comes in. This is a homework question that shows how well one understands the notion of variance, as well as the fact that multiplying a random variable by a constant increases the variance by the square of the constant. You can check that if the two hedge funds have the same variance then diversifying by investing 50$ in each hedge fund is the wisest choice from a risk aversion perspective.
Risk aversion is an exciting topic. Humans do not need to know probability theory formally to take risk averse decisions. Daniel Bernoulli in 1738 studied why humans are risk averse, and why risk aversion decreases with wealth in a remarkable essay that I urge you to read. For instance, if one suggests you to get 1000$ with probability 0.85 (0$ with probability 0.15), or 800$ with probability 1, it is likely that you will prefer the latter option, even if in expectation you are better off to gamble.
Recently, Shreyas Sekar, Johnson Lam, Liu Yang and I studied the problem of maximum weight matchings in uncertain hypergraphs. Just as in the case of the two hedge funds, we may want a heavy weight matching, but on the other hand we want to make sure that the risk is bounded. Specifically, we studied the following question:
Given an uncertain, weighted (hyper)graph, how can we efficiently find a (hyper)matching with high expected reward, and low risk?
For the case of uncertain weighted graphs, we provide a 
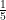


An interesting open research direction is to provide risk averse, efficient algorithms for graph mining problems in uncertain graphs and hypergraphs. The interested reader can find all the details in our Arxiv paper here.
