
How can we find whether there exists a large set of vertices that is a clique or close to being a clique modulo few missing edges? This is a key problem for many important applications.
Motivation: Suppose you are given a large “who-calls-whom” network. This is a network where each vertex represents a human and we have an (undirected) edge between two humans if and only if they exchanged a phone call. An important problem that comes up in anomaly detection is finding sets of vertices that “look like” cliques. There are different ways to quantify what “looks like” precisely means, but for now we will think of this as a subgraph which is close to being fully interconnected modulo few missing edges. Large sets of such vertices are contradicting to the average human habits: who talks to say 50 people who all talk among each other as well? The problem of finding such sets of vertices is a hard problem. More importantly, this problem comes up in many real-world applications, including correlation mining, graph visualization, data mining, bioinformatics and drug discovery.
We will use the following notation: let 
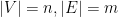



Related work: The maximum clique problem is NP-complete and even worse -unless P=NP- there can be no polynomial time algorithm that approximates the maximum clique to within a factor better than 

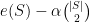

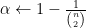
It is impossible to exhaust the existing work related to the problem of dense subgraph discovery. However, here is a set of available algorithmic tools.
- Brute force, which is possible if
is small enough.
- Heuristics of all kinds. Such methods suffer from at least one of the following drawbacks: (i) they are not well understood, (ii) they frequently fail (iii) they do not scale well.
- Maximal clique enumeration methods.
- Spectral methods
- NP-hard formulations and various relaxations
- Poly-time solvable objectives
The latter family constitutes a major algorithmic toolbox. Among poly-time solvable objectives the densest subraph problem stands out. To quote a paper due to Bahmani, Kumar and Vassilvitski, “The densest subgraph problem lies at the core of large scale data mining”.
Densest subgraph problem: The goal is to find


- The densest subgraph problem is solvable in polynomial time. The most efficient exact method relies on parametric maximum flow methods.
- There exists a 2-approximation peeling algorithm which uses linear space
and runs in linear time
- On many real-world instances, the densest subgraph problems returns large sets of vertices with low edge density. Here is an extreme example: on a small network with 115 vertices and 613 edges (Football network), the densest subgraph is the whole network.
k-clique densest subgraph problem: A couple of months ago, I presented at WWW’15 my work “The K-clique densest subgraph problem“. This problem generalized the densest subgraph problem. Specifically, the problem is to maximize over all possible 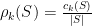



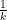
- For k=2, the optimal solution is a set of 18,686 vertices with edge density 0.11.
- For k=3, the optimal solution is a set of 76 vertices with edge density 0.80.
- For k=4, the optimal solution is a set of 62 vertices with edge density 0.96.
Scalability: Essentially, in the worst case, the run time depends exponentially on 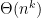
References
[1] The K-clique Densest Subgraph Problem
[2] Scalable Large Near-Clique Detection in Large-Scale Networks via Sampling

[…] Security applications: See my previous post here. […]