Suppose that we have a sample of 
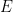



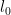
Idea: When an update takes place, we will invoke just one -rather than K- ![E^* = {[n] \choose 2} \supseteq E^{(t)}](https://s0.wp.com/latex.php?latex=E%5E%2A+%3D+%7B%5Bn%5D+%5Cchoose+2%7D+%5Csupseteq+E%5E%7B%28t%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)


- Let
be an
-wise independent hash function
- The
-th “bucket”
is responsible for all edges such that
, for each
. We also run an independent copy of an
- When an update takes place, we hash the resulting inserted or deleted edge
and invoke the corresponding
- The overall type of guarantee one would like to get is that the probability of an edge being in the sample is
. Also, one would like to make probabilistic statements that hold with high probability for all updates and for all vertices. This goal determines the

For all the technical details and the formal statement of the results, take a look at [Lemma 4.3, 1] which is joint work with Sayan Bhattacharya, Monika Henzinger and Danupon Nanongkai.
References
[1] Space- and Time-Efficient Algorithm for Maintaining Dense Subgraphs on One-Pass Dynamic Streams, STOC 2015 by Sayan Bhattacharya, Monika Henzinger and Danupon Nanongkai and Charalampos E. Tsourakakis
