Latent feature learning: where overlapping communities, correlation clustering, binary matrix factorization and extremal graph theory meet
Motivation: Suppose we are given the following.
- Agents: Five agents, represented by
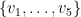 .
.
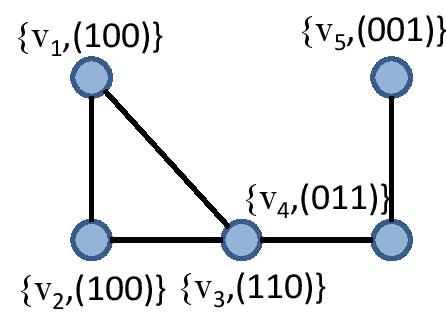
- Binary vertex features. An agent can either be interested or not in each out of three news categories business, entertainment, sports. Each interest is represented by a binary feature. For instance, in the figure below,
 is interested only in business news.
is interested only in business news.
- Connection rule. Two agents connect iff they share at least one common interest.
Given this information, it is straightforward to generate the graph. For instance, is connected to 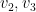 since they share their interest in business news. However there are no edges between and
since they share their interest in business news. However there are no edges between and 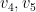 as they share no common interests.
as they share no common interests.

In principle, the connection rule is probabilistic. In that case, we can sample a graph with the correct probability.
Here is a fundamental inverse problem: we are given an unweighted, undirected graph  , the number of binary features
, the number of binary features  , but we are not given the binary vertex features. How do we learn (a good setting of) the binary features? This is a fundamental learning problem on networks with many related applications. This set of applications includes overlapping community detection: think that features correspond to communities as in the following figure. What we see are two overlapping communities. Vertices that belong to both communities are labeled as 11, whereas the rest are labeled as 10 or 01.
, but we are not given the binary vertex features. How do we learn (a good setting of) the binary features? This is a fundamental learning problem on networks with many related applications. This set of applications includes overlapping community detection: think that features correspond to communities as in the following figure. What we see are two overlapping communities. Vertices that belong to both communities are labeled as 11, whereas the rest are labeled as 10 or 01.

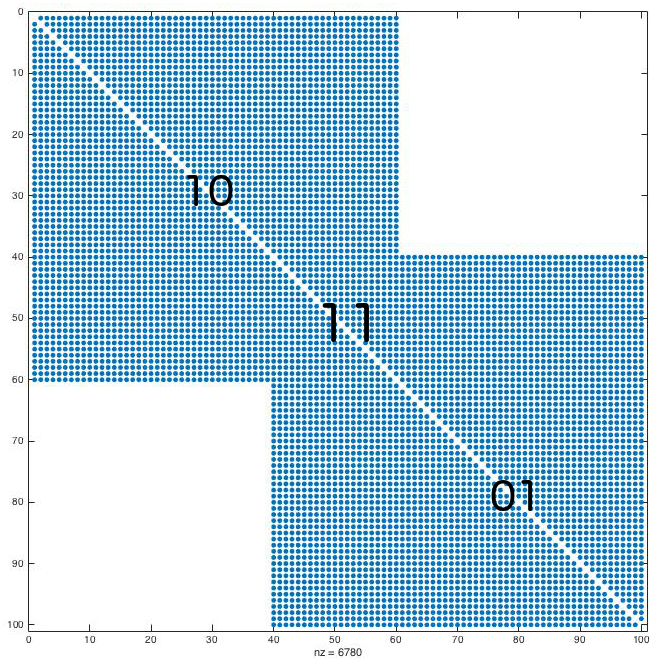
However, on real data the communities are far away from being as dense as shown above. They are more likely to look like the following figure. As you observe the communities are sparser. Also, the overlap is denser than the two counterparts. This is not necessarily always true, but as Yang and Leskovec point out, this is frequently the case in social networks.
 Despite the obvious conceptual connection between latent feature learning and overlapping community detection, the two problems are not the identical. For the graph shown in the first figure, any good algorithms will output the same result. However, things are different for the sparser graph shown in the second figure.
Despite the obvious conceptual connection between latent feature learning and overlapping community detection, the two problems are not the identical. For the graph shown in the first figure, any good algorithms will output the same result. However, things are different for the sparser graph shown in the second figure.
Any good overlapping community detection method will output two communities, just as in figure 1. However, Bayesian non-parametric methods -a prominent class of latent feature learning methods- will attempt to explain the sparsity within each community by using a value of greater than 2, despite the existence of two communities. From this point of view, they can seen as refined overlapping community detection methods. The latent feature learning problem touches various research lines, including binary matrix factorization, machine learning and graph analysis. For more details, see the related work section in my recent WWW’15 paper. One thing that I realized by experimenting with various state-of-art machine learning methods is that Bayesian non-parametric methods are accurate but they don’t scale well. This makes them useful for relatively small networks. The component that appears to be the main bottleneck for scaling up such methods is the poor mixing of a Markov chain on which they rely.
Some results from Ref. [1]: Last year I became interested in the latent feature learning problem. I considered a simple probabilistic model according to which the probability of an edge is a non-decreasing function of the common interests of the the two endpoints. The probabilistic setting follows.
- Number of features.
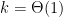 (known)
(known)
- Latent labeling.
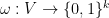
- Vertex “interests”. Define for each vertex
 the set
the set  of non-zero coordinates. E.g., if
of non-zero coordinates. E.g., if  then
then  .
.
- Connection rule. Let
 be a threshold parameter. Vertex establishes its connections with other vertices based on the following simple rule:
be a threshold parameter. Vertex establishes its connections with other vertices based on the following simple rule:
 , then add edge
, then add edge  with probability
with probability  .
.- If
 , then add edge with probability
, then add edge with probability  .
.
Notice that when  the resulting random graph model is the
the resulting random graph model is the  model. However, for
model. However, for  we obtain an interesting random graph setting. This model is reminiscent of an overlapping version of the planted partition model. Based on this probabilistic model we can write down the likelihood function of a graph given the latent labeling
we obtain an interesting random graph setting. This model is reminiscent of an overlapping version of the planted partition model. Based on this probabilistic model we can write down the likelihood function of a graph given the latent labeling  . We use
. We use  . Specifically,
. Specifically, 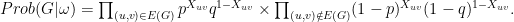
Here, 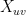 is an indicator variable equal to 1 iff
is an indicator variable equal to 1 iff  share at least one common interest. By taking logarithms we find that the log-likelihood function equals
share at least one common interest. By taking logarithms we find that the log-likelihood function equals  where
where 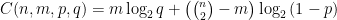 is a constant that does not depend on the labeling and
is a constant that does not depend on the labeling and ![\bar{E}(G) = {[n] \choose 2} \backslash E(G)](https://s0.wp.com/latex.php?latex=%5Cbar%7BE%7D%28G%29+%3D+%7B%5Bn%5D+%5Cchoose+2%7D+%5Cbackslash+E%28G%29&bg=ffffff&fg=000000&s=0&c=20201002) . Here is a nice observation. If we set
. Here is a nice observation. If we set  (notice that in general their sum need not be one) we obtain the overlapping correlation clustering (OCC) objective, namely
(notice that in general their sum need not be one) we obtain the overlapping correlation clustering (OCC) objective, namely  . This objective was introduced by Bonchi et al. and was shown to be NP-hard. So we know that our problem is NP-hard in general. Bonchi et al. introduced in their work a heuristic that in certain cases works surprisingly well, given its simplicity. You can take a look in their paper for the details but here is the rough idea: perform a systematic scan of the vertices and for each vertex change its labeling in a way that increases the objective value. One could choose any labeling that increases the objective or choose greedily the labeling that results in the largest increase. Here is another observation: their algorithm is a deterministic hill climbing heuristic even if it is not explicitly stated in their paper. Furthermore, their method works only for dense graphs. To see why, suppose that I give you a graph with
. This objective was introduced by Bonchi et al. and was shown to be NP-hard. So we know that our problem is NP-hard in general. Bonchi et al. introduced in their work a heuristic that in certain cases works surprisingly well, given its simplicity. You can take a look in their paper for the details but here is the rough idea: perform a systematic scan of the vertices and for each vertex change its labeling in a way that increases the objective value. One could choose any labeling that increases the objective or choose greedily the labeling that results in the largest increase. Here is another observation: their algorithm is a deterministic hill climbing heuristic even if it is not explicitly stated in their paper. Furthermore, their method works only for dense graphs. To see why, suppose that I give you a graph with 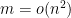 . Then, since the first summation term (over edges) is negligible with respect to the second term (non-edges), we can set
. Then, since the first summation term (over edges) is negligible with respect to the second term (non-edges), we can set  for all vertices. Similarly, if we have more edges than non-edges, we can satisfy them by setting
for all vertices. Similarly, if we have more edges than non-edges, we can satisfy them by setting 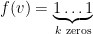 . Since in real-world networks the OCC formulation is not suitable. This observation also shows that obtaining a constant factor approximation algorithm is trivial. One result in [1] is to provide a rapidly mixing Metropolis chain. whose stationary distribution favors the states that achieve a high likelihood score. The second question that to my knowledge had not been asked by latent feature learning methods on graphs, is what kind of graph substructures force us to use large k values in order to achieve a good score. It turns out that bipartite cliques make the problem hard. This is intuitive. If my neighborhood
. Since in real-world networks the OCC formulation is not suitable. This observation also shows that obtaining a constant factor approximation algorithm is trivial. One result in [1] is to provide a rapidly mixing Metropolis chain. whose stationary distribution favors the states that achieve a high likelihood score. The second question that to my knowledge had not been asked by latent feature learning methods on graphs, is what kind of graph substructures force us to use large k values in order to achieve a good score. It turns out that bipartite cliques make the problem hard. This is intuitive. If my neighborhood  is a stable set, then I have a common interest with
is a stable set, then I have a common interest with  . I Also have a common interest with
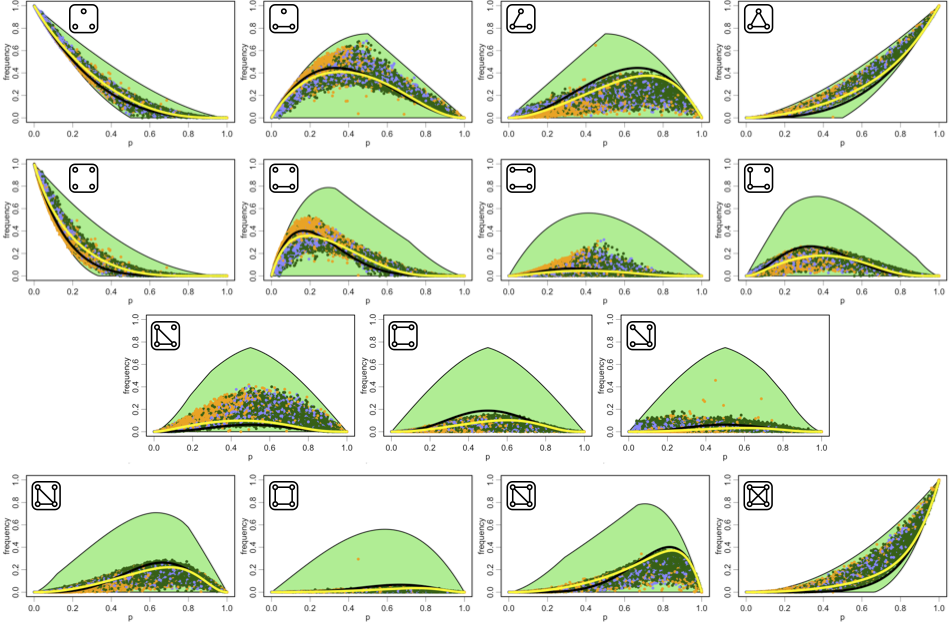
. I Also have a common interest with  . But since and are not connected there have to be two different features and so on. This is interesting when you combine it with the empirical fact that existing latent feature learning methods achieve good scores on co-authorship graphs and social networks with low values. This suggests that there are not large bipartite cliques on these networks. Indeed, Ugander et al. studied how frequently certain small subgraphs appear in real-world networks.
. But since and are not connected there have to be two different features and so on. This is interesting when you combine it with the empirical fact that existing latent feature learning methods achieve good scores on co-authorship graphs and social networks with low values. This suggests that there are not large bipartite cliques on these networks. Indeed, Ugander et al. studied how frequently certain small subgraphs appear in real-world networks.

Source: people.cam.cornell.edu/~jugander/subgraphs/
It turns out that social networks have a strikingly small number of induced cycles of length 4, i.e., usually denoted as 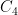 s. This makes sense. If there were large bipartite cliques, then we would have many s.
s. This makes sense. If there were large bipartite cliques, then we would have many s.
Open problems. Some interesting research directions include:
- Combinatorial understanding of latent feature learning methods for graphs.
- Richer family of probabilistic models for undirected graphs for which we can have efficient (approximation) algorithms?
- New probabilistic models and latent feature learning algorithms for directed graphs.
References
[1] “Provably Fast Inference of Latent Features from Networks“, Charalampos E. Tsourakakis, WWW’15
 Despite the obvious conceptual connection between latent feature learning and overlapping community detection, the two problems are not the identical. For the graph shown in the first figure, any good algorithms will output the same result. However, things are different for the sparser graph shown in the second figure.
Despite the obvious conceptual connection between latent feature learning and overlapping community detection, the two problems are not the identical. For the graph shown in the first figure, any good algorithms will output the same result. However, things are different for the sparser graph shown in the second figure.