
Lycurgus consulting Pythia
Pythia was a powerful and respected woman in Ancient Greece. She was the high priestess of the Temple of Apollo at Delphi. I was surprised to read in the Wikipedia article that the name Pythia is derived from the verb πύθειν (púthein) which means “to rot”; I find this to be unlikely. An etymology that sounds more likely is that the root is the verb “πυνθάνομαι” which means to get informed. Pythia served as the Oracle, namely she was making predictions but some of these predictions were notoriously ambiguous. An example: once a man went to ask whether his wife would give birth to a boy or a girl. Pythia replied “άρρεν ου θήλυ” or in English “male not female”. This is an ambiguous answer, depending on where one places the comma, i.e., “male not, female” vs “male, not female”. Oracles are noisy due to the inherent uncertainty in predicting the future. Pythia was definitely doing her best in order to claim that her predictions were correct no matter the future outcome.
Clustering with a faulty oracle
Social interactions can be positive or negative. Can we predict the sign of an unknown interaction using information about the rest of the interactions in a social network? Jure Leskovec, Dan Huttenlocher, and Jon Kleinberg [1] formalized the question of predicting the unknown sign of an edge using information about the rest of the edges of the graph.
 In a joint work with Michael, Kasper, Jarek, Ben, Preetum and Vasilis we modeled this task as a noisy correlation clustering problem. Specifically, we assume there are two clusters of nodes that are unknown to us. Inspired by the balance theory, we assume that interactions within clusters are positive, and across negative. We can choose any pair of nodes once to query and get a noisy answer on whether they belong to the same cluster or not. Let’s assume that we get the correct answer with probability
In a joint work with Michael, Kasper, Jarek, Ben, Preetum and Vasilis we modeled this task as a noisy correlation clustering problem. Specifically, we assume there are two clusters of nodes that are unknown to us. Inspired by the balance theory, we assume that interactions within clusters are positive, and across negative. We can choose any pair of nodes once to query and get a noisy answer on whether they belong to the same cluster or not. Let’s assume that we get the correct answer with probability 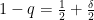
We provide two algorithms for this problem. The first algorithm is called Pythia2Truth and has the following properties stated as the next theorem .
Theorem: There exists an algorithm that runs in 


While the algorithm is simple to describe and implement, it improves the state-of-the-art results of a last year’s NIPS paper [3]. Essentially, for all except tiny delta, it achieves exact recovery with 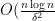
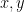
Theorem: Let 
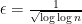

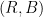

Edge sign prediction
From an empirical point of view, we extend the framework of Leskovec-Huttenlocher-Kleinberg by adding path based features in the set of features used to train a logistic regression. We report several findings on real world datasets in our paper. We found some of them to be surprising. For instance, edge disjoint paths of length 3 between two nodes can be more informative than triads, but edge disjoint paths of length 4 or greater are not. Our addition gives significantly improved classification results for edges with zero or small number of common neighbors. You can find the details in our paper.
Open problem
Can we extend our results to the case of 
References
[1] Predicting Positive and Negative Links in Online Social Networks, https://arxiv.org/abs/1003.2429
[2] Predicting Positive and Negative Links with Noisy Queries: Theory & Practice, https://arxiv.org/abs/1709.07308
[3] Clustering with Noisy Queries, https://arxiv.org/abs/1706.07510
